

写在前面
在云原生的时代,可观测性(Observability) 已经成为系统稳定运行的核心能力之一。随着业务规模的不断扩大,单机监控已无法满足分布式系统的需求,构建一套高效、可扩展的监控体系显得尤为重要。
本文将基于 Kubernetes(K8S) 环境,完整搭建一套 Prometheus + Grafana + Alertmanager 的监控与告警系统,实现从 数据采集、可视化展示到告警通知 的全链路监控闭环。
1. node-exporter的组件安装和配置
1.1 node-exporter 介绍
node-exporter 可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包 括 CPU, 内存,磁盘,网络,文件数等信息。
1.2 安装node-exporter组件
网络有限制的朋友可以使用我下载好的:node-exporter
--- 1. 创建名称空间
[root@k8s-master /manifests/daemonset]# kubectl create ns monitor-sa
--- 2. 使用daemonset控制器
[root@k8s-master /manifests/daemonset]# cat node_export.yaml
apiVersion: apps/v1
## 可以保证 k8s 集群的每个节点都运行完全一样的 pod
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
## 可以看到宿主机里正在运行的所有进程
hostPID: true
## 直接与宿主机进行 IPC(进程间通信)通信
hostIPC: true
## 使用宿主机网络,同时会把宿主机的9100端口映射出来,这样就不需要创建service了。
hostNetwork: true
## 这个 Pod 可以容忍 master 节点上的 node-role.kubernetes.io/master 这个污点,可以调度到 master 节点上运行
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
## 持久化存储
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
containers:
- name: node-exporter
## 这里我用的是镜像仓库,也可以直接使用本地镜像
image: 192.168.0.77:32237/k8s/node-exporter:latest
ports:
- containerPort: 9100
resources:
requests:
## 这个容器运行至少需要CPU的核心数
cpu: 0.15
securityContext:
## 开启容器的特权模式
privileged: true
args:
## 配置挂载宿主机(node 节点)的路径
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
## 将主机/dev、/proc、/sys 这些目录挂在到容器中,这是因为我们采集的很多节点数据都是通过这些文件来获取系统信息的
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
--- 3. 通过 kubectl apply 更新 node-exporter.yaml 文件
[root@k8s-master /manifests/daemonset]# kubectl apply -f node_export.yaml
## 查看pod 是否正常
[root@k8s-master /manifests/daemonset]# kubectl get pod -n monitor-sa
--- 4. 通过 node-exporter 采集数据
curl http://主机 ip:9100/metrics
# node-export 默认的监听端口是 9100,可以看到当前主机获取到的所有监控数据
[root@k8s-master /manifests/daemonset]# curl 192.168.0.163:9100/metrics |grep node_cpu_seconds
[root@k8s-master /manifests/daemonset]# curl 192.168.0.163:9100/metrics |grep node_load
node_load1 该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此 node_load1 反映的是当前状态,数据可能增加也可能减少
2. Prometheus server组件的安装和配置
2.1 创建sa账号,对sa做rbac 授权
## 创建sa账号
[root@k8s-master /manifests/daemonset]# kubectl create serviceaccount monitor -n monitor-sa
[root@k8s-master /manifests/daemonset]# kubectl create clusterrolebinding monitor-clusterrolebinding --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
## 参数解释
kubectl create clusterrolebinding ## 创建一个集群级别的角色绑定(ClusterRoleBinding)
monitor-clusterrolebinding ## 这是 ClusterRoleBinding 资源的名字(随便取,用来标识这个绑定)
clusterrole=cluster-admin ## 指定要绑定的 ClusterRole,这里是 cluster-admin(内置的超级管理员角色)
serviceaccount=monitor-sa:monitor ## 指定绑定的 ServiceAccount,格式 名称空间:服务名,表示这个 SA 将获得上面 ClusterRole 的权限。2.2 创建pv和pvc做数据持久化
--- 1. 创建目录
[root@k8s-master /data/nfs]# mkdir -p /data/nfs/prometheus
## 权限最好是65534 不然可能会启动不了
[root@k8s-master /data/nfs]# chown -R 65534:65534 prometheus/
## 创建pv,这里我使用K8S自带的nfs 存储,如果有变化的要自行修改哦
--- 2. 创建pv
## 怎么创建nfs存储可以在我其他文章里有提过
[root@k8s-master /manifests/pv]# cat prometheus-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-pv
namespace: monitor-sa
spec:
accessModes:
- ReadWriteMany
nfs:
server: 192.168.0.160
path: /data/nfs/prometheus
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 2Gi
--- 3. 创建pvc
[root@k8s-master /manifests/pv]# cat prometheus-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-pvc
namespace: monitor-sa
spec:
## 声明资源的访问模式
accessModes:
- ReadWriteMany
## 声明资源的使用量
resources:
requests:
storage: 2Gi
## 绑定上面的pv
volumeName: prometheus-pv2.3 创建一个 configmap 存储卷,用来存放 prometheus 配置信息
[root@k8s-master /manifests/configmap]# cat prometheus-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
global:
## 采集目标主机监控据的时间间隔
scrape_interval: 15s
## 数据采集超时时间,默认 10s
scrape_timeout: 10s
## 触发告警检测的时间,默认是 1m
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
## 使用的是 k8s 的服务发现
kubernetes_sd_configs:
## 使用 node 角色,它使用默认的 kubelet 提供的 http 端口来发现集群中每个 node 节点
- role: node
## 重新标记
relabel_configs:
## 匹配原始标签,匹配地址
- source_labels: [__address__]
## 匹配带有10250端口的url
regex: '(.*):10250'
## 把匹配到的IP:10250的ip保留下来
replacement: '${1}:9100'
## 新生成的 url 是${1}获取到的 ip:9100
target_label: __address__
action: replace
- action: labelmap
## 匹配到下面正则表达式的标签会被保留,如果不做 regex 正则的话,默认只是会显示 instance 标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
## 抓取 cAdvisor 数据,是获取 kubelet 上/metrics/cadvisor 接口数据来获取容器的资源使用情况
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
## 把匹配到的标签保留
- action: labelmap
## 保留匹配到的具有__meta_kubernetes_node_label 的标签
regex: __meta_kubernetes_node_label_(.+)
## 获取到的地址:__address__="192.168.0.160:10250"
- target_label: __address__
## 把获取到的地址替换成新的地址 kubernetes.default.svc:443
replacement: kubernetes.default.svc:443
## 把原始标签中__meta_kubernetes_node_name 值匹配到
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
## 使用 k8s 中的 endpoint 服务发现,采集 apiserver 6443 端口获取到的数据
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
## endpoint 这个对象的名称空间,服务名称,端口名称
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
## 采集满足条件的实例,其他的不采集
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
## 重新打标仅抓取到的具有 "prometheus.io/scrape: true" 的 annotation 的端点,
#意思是说如果某个 service 具有 prometheus.io/scrape = true annotation 声明则抓取,
#annotation 本身也是键值结构,所以这里的源标签设置为键,而 regex 设置值 true,当值匹配到 regex 设定的内容时则执行 keep 动作也就是保留,其余则丢弃。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
## 重新设置 scheme,匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme
#也就是 prometheus.io/scheme annotation,如果源标签的值匹配到 regex,则把值替换为__scheme__对应的值。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
## 应用中自定义暴露的指标,也许你暴露的 API 接口不是/metrics 这个路径,
#那么你可以在这个POD 对应的 service 中做一个"prometheus.io/path = /mymetrics" 声明,
#上面的意思就是把你声明的这个路径赋值给__metrics_path__,其实就是让 prometheus 来获取自定义应用暴露的 metrices 的具体路径,
#不过这里写的要和 service 中做好约定,如果 service 中这样写 prometheus.io/app-metrics-path:'/metrics' 那么你这里就要 __meta_kubernetes_service_annotation_prometheus_io_app_metrics_path 这样写
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
## 暴露自定义的应用的端口,就是把地址和你在 service 中定义的 "prometheus.io/port = <port>" 声明做一个拼接,
#然后赋值给__address__,这样 prometheus 就能获取自定义应用的端口,
#然后通过这个端口再结合__metrics_path__来获取指标,如果__metrics_path__值不是默认的/metrics 那么就要使用上面的标签替换来获取真正暴露的具体路径。
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name 2.4 通过 deployment 部署 prometheus
如果网络有限制的朋友可以使用我下载好的镜像:prometheus-server
[root@k8s-master /manifests/deployment]# cat prometheus-server.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
## 指定pod调度的节点
## 在k8s集群的哪个节点创建数据目录,就让 pod 调度到哪个节点
nodeName: k8s-master
serviceAccountName: monitor
securityContext:
runAsUser: 65534
runAsGroup: 65534
fsGroup: 65534
containers:
- name: prometheus
## 这里的镜像在我的私有仓库哦
image: 192.168.0.77:32237/prom/prometheus:v2.53.5
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
## 旧数据的存储目录
- --storage.tsdb.path=/prometheus
## 何时删除旧数据,默认15天
- --storage.tsdb.retention=720h
## 开启热加载
- --web.enable-lifecycle
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
hostPath:
path: /data/nfs/prometheus
type: Directory2.5 创建service
[root@k8s-master /manifests/service]# cat prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
## 更新service
[root@k8s-master /manifests/service]# kubectl apply -f prometheus-svc.yaml
## 查看 service 在物理机映射的端口
[root@k8s-master /manifests/service]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.200.162.114 <none> 9090:31326/TCP 80m
## 通过上面可以看到 service 在宿主机上映射的端口是 31326,这样我们访问 k8s 集群的 master 节点的 ip:31326,就可以访问到 prometheus 的 web ui 界面了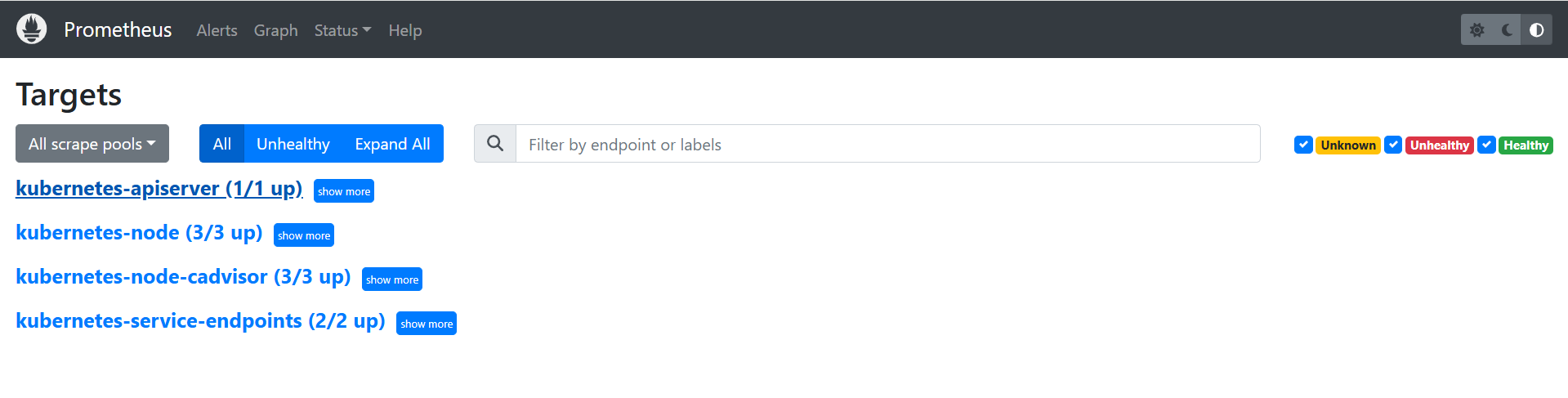
2.6 Prometheus 热加载
## 为了每次修改配置文件可以热加载 prometheus,也就是不停止 prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令:
[root@k8s-master /manifests/service]# kubectl get pod -owide -n monitor-sa -l app=prometheus
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-server-844b4b7c9b-pqqnd 1/1 Running 0 88m 10.100.235.206 k8s-master <none> <none>
## 我们可以看出pod的ip是10.100.235.206
## 想要使配置生效可用如下命令热加载
[root@k8s-master /manifests/service]# curl -X POST http://10.100.235.206:9090/-/reload
## 热加载速度比较慢,可以暴力重启 prometheus 删除yaml文件的方式,但是线上最好热加载,暴力删除可能造成监控数据的丢失! 3. 安装Grafana
3.1 通过deployment 部署grafana
[root@k8s-master /manifests/deployment]# cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
initContainers:
- name: init-grafana-data
image: busybox:1.28
command:
- sh
- -c
- |
mkdir -p /var/lib/grafana/plugins
chown -R 472:472 /var/lib/grafana
volumeMounts:
- name: grafana-storage
mountPath: /var/lib/grafana
containers:
- name: grafana
image: 192.168.0.77:32237/k8s/grafana:latest
ports:
- containerPort: 3000
protocol: TCP
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
volumes:
- name: grafana-storage
emptyDir: {}
- name: ca-certificates
hostPath:
path: /etc/ssl/certs3.2 创建service
[root@k8s-master /manifests/service]# cat grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort3.3 Grafana 界面接入 Prometheus 数据源
--- 1. 查看 grafana 前端的 service
[root@k8s-master /manifests/service]# kubectl get svc -n kube-system |grep grafana
monitoring-grafana NodePort 10.200.164.156 <none> 80:31593/TCP 87s
--- 2. 浏览器登录 192.168.0.160:31593
## 默认账号密码登录: 账号 admin 密码: admin
## 添加数据源,搜索prometheus
## 连接的地址:
http://prometheus.monitor-sa.svc:9090
## prometheus → Kubernetes 中你 Prometheus 服务的名字(Service 名)
## monitor-sa → Prometheus 所在的 Namespace
## svc → Kubernetes 内部 DNS 的固定后缀,表示这是一个 Service。
## :9090 → Prometheus 服务的端口号(默认 9090)我这里两份模板觉得还不错,分别是监控docker和K8S的模板,可以导入体验一下
docker: docker.json
K8S: node_exporter.json
4. 配置 alertmanager-发送报警到个人邮箱
报警:指 prometheus 将监测到的异常事件发送给 alertmanager
通知:alertmanager 将报警信息发送到邮件、微信、钉钉等
4.1 创建 alertmanager 配置文件
[root@k8s-master /manifests/configmap]# cat altermanager.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 5m
## 这是指定从哪个邮箱发送报警
smtp_from: 'xing775288271@163.com'
## 163 邮箱的 SMTP 服务器地址+端口
smtp_smarthost: 'smtp.163.com:465'
smtp_hello: '163.com'
## 发送邮箱的认证用户,不是邮箱名
smtp_auth_username: 'xing775288271@163.com'
## 授权码
smtp_auth_password: 'DHTqgQ6pF9kb8FGg'
smtp_require_tls: false
## 用于配置告警分发策略
route:
## 采用哪个标签来作为分组依据
group_by: [alertname]
## 组告警等待时间。也就是告警产生后等待 10s,如果有同组告警一起发出
group_wait: 10s
## 上下两组发送告警的间隔时间
group_interval: 10s
## 重复发送告警的时间,减少相同邮件的发送频率,默认是 1h
repeat_interval: 10m
## 定义谁来收告警
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
## 后面指定发送到哪个邮箱,我发送到我的企业邮箱
- to: 'xingzhibang@pexetech.com'
send_resolved: true4.2 创建altermanager的告警规则配置文件
我这里有写好的配置文件模板,可以用一下:prometheus-alertmanager-cfg.yaml
## 文件需要修改内容如下:
...
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
## scheduler 组件所在节点的 ip
- targets: ['192.168.0.160:10251']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
## controller-manager组件所在节点的 ip
- targets: ['192.168.0.160:10252']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
## kube-proxy 组件所在节点的 ip
- targets: ['192.168.0.160:10249','192.168.0.162:10249','192.168.0.163:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
## kube-proxy 组件所在节点的 ip
- targets: ['192.168.0.160:2379']4.3 通过 deployment 部署 altermanager
网络有限制的朋友可以使用我下载好的altermanager镜像:altermanager.tar.gz
## 配置文件指定了 nodeName 要写你自己环境的 k8s 的 node 节点名字哦
[root@k8s-master /manifests/deployment]# cat prometheus-alertmanager.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-alertmanager
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: k8s-master
serviceAccountName: monitor
containers:
- name: alertmanager
## 这里使用的是我的镜像仓库
image: 192.168.0.77:32237/k8s/alertmanager:latest
args:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
protocol: TCP
name: alertmanager
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager-storage
mountPath: /alertmanager
- name: localtime
mountPath: /etc/localtime
volumes:
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager-storage
hostPath:
path: /data/alertmanager
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai 4.4 创建service
[root@k8s-master /manifests/service]# cat alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
name: prometheus
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: prometheus
sessionAffinity: None
type: NodePort
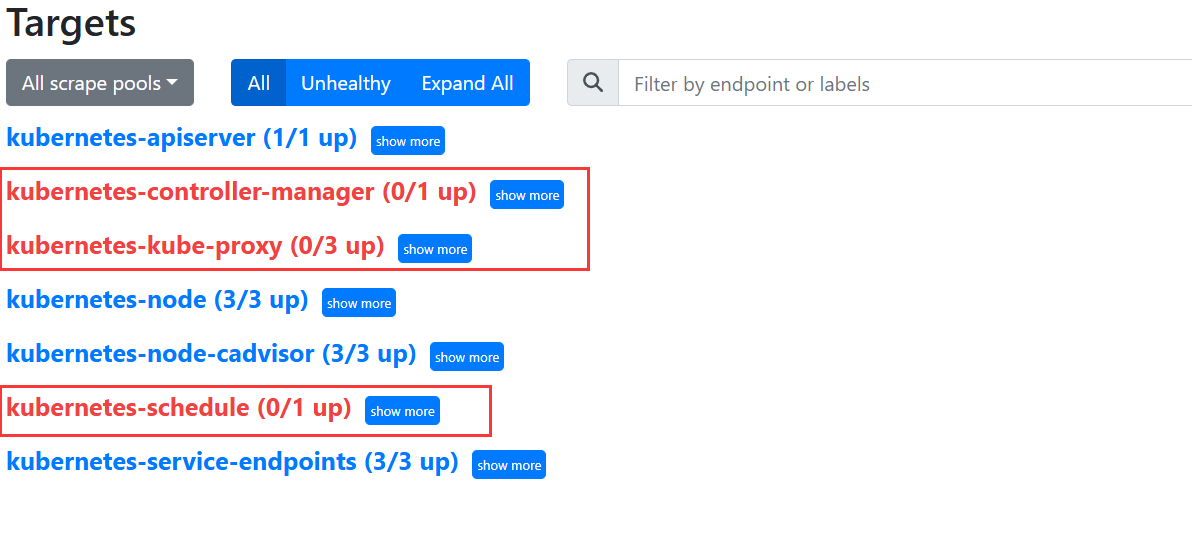
## service 在物理机映射的端口是 30066 重启Prometheus的pod后发现有个问题,这三个节点显示连接不上对应的端 口:
评论